Saturday. Four minutes on the clock. Pitching to judges from Anthropic, Google, Ramp, Stripe, and MongoDB.

The prompt for the day was simple: find a marketing process that's inhuman in scope or scale, and ship a system that runs it.
That's it. Eight hours. Go.
What I built
I called it Flagship Video.
The idea: most brands are invisible in AI search and have no idea where. Flagship reads that gap from Profound's data, finds the queries where you don't show up, and then generates the video to close it.
Why video. YouTube is one of the most-cited sources across every major AI engine. When ChatGPT or Perplexity answers a question, it's often pulling from a video. But almost no brand can produce video at the scale that real AI search presence takes.

So Flagship connects the data showing the opportunity directly to the asset that fills it. Point it at a domain and a category, and it scores every prompt where you're not cited.
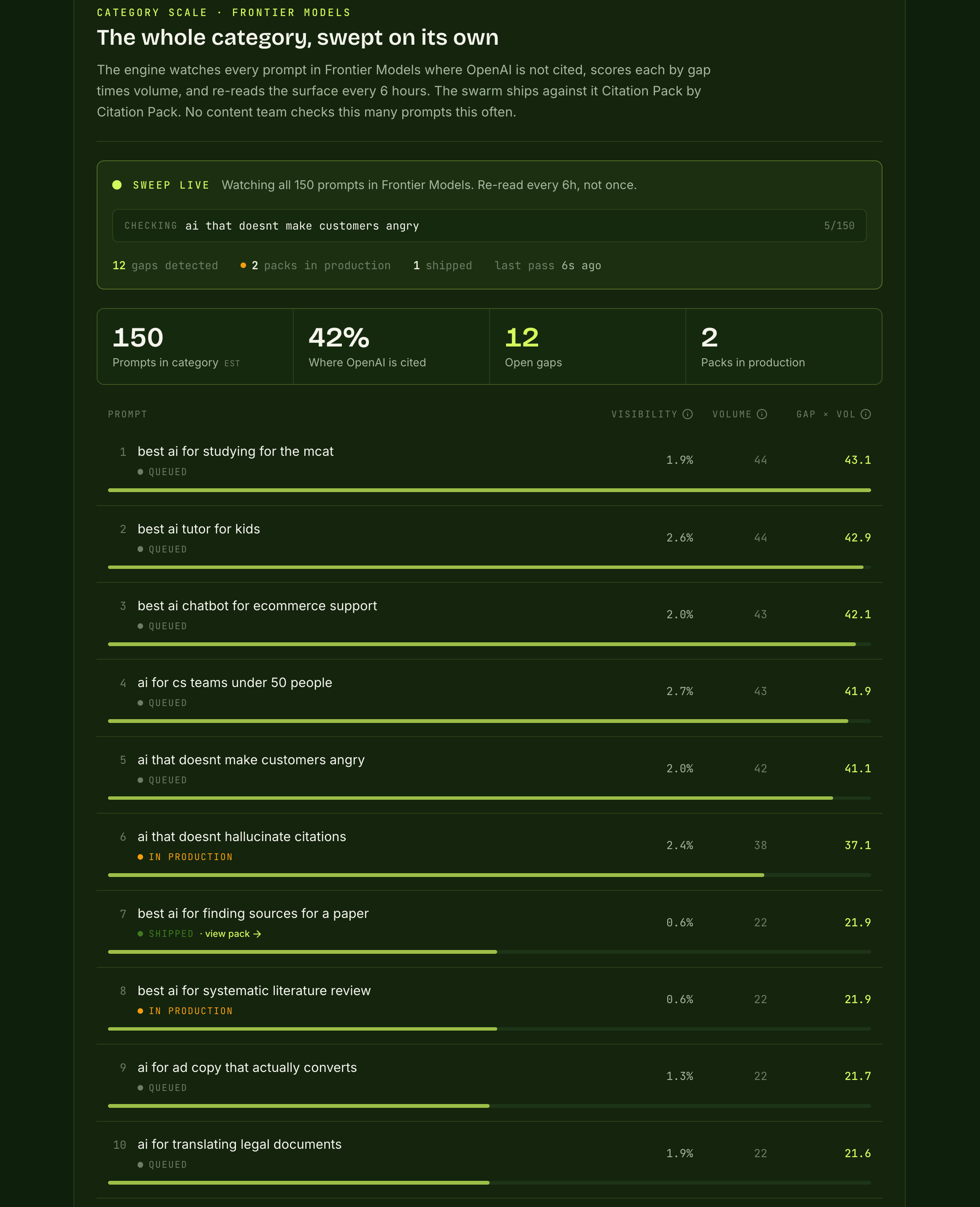
The gap tells you what to make. The system makes it. The output is a full Citation Pack: the video, captions, a companion article, and the schema.
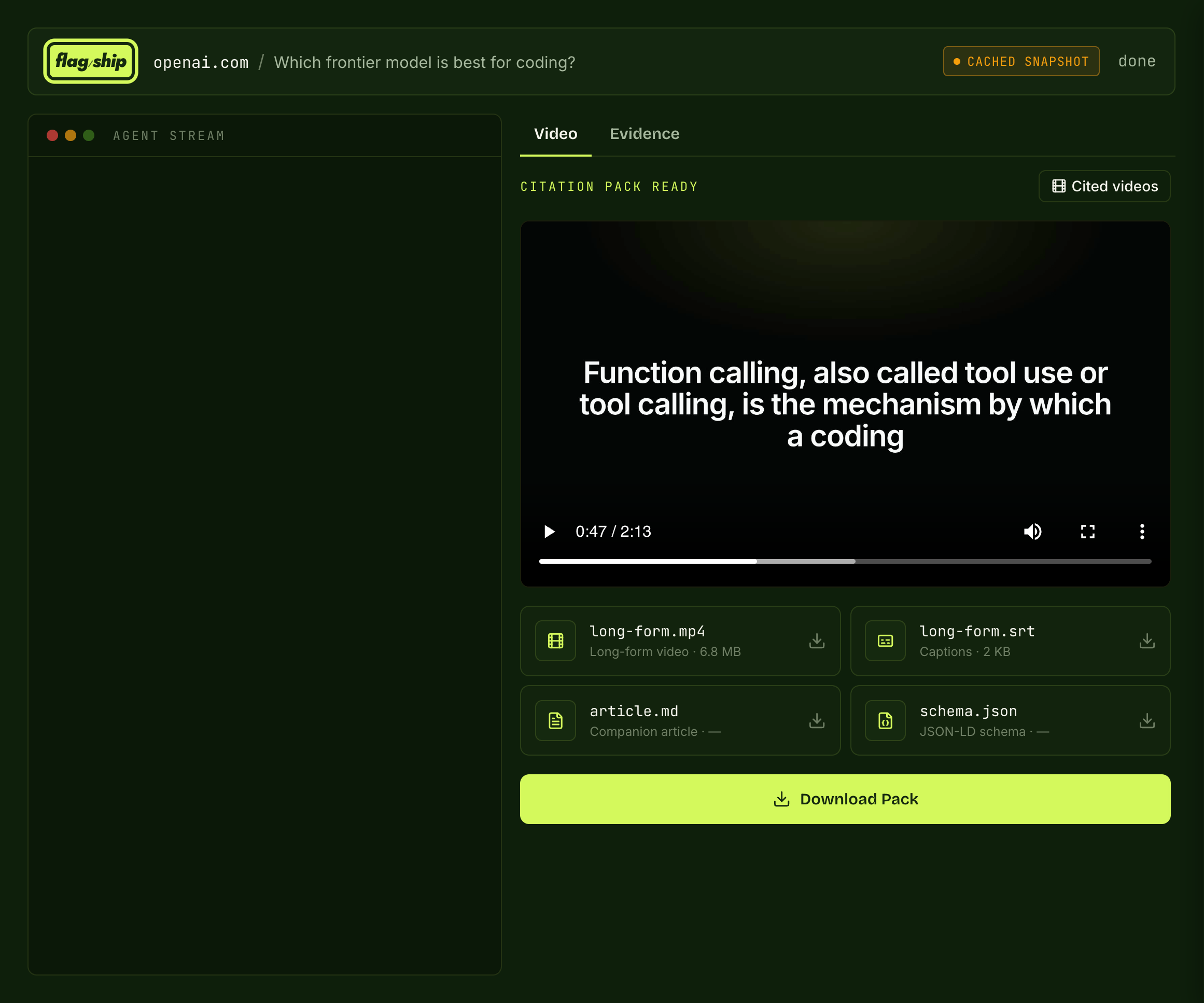
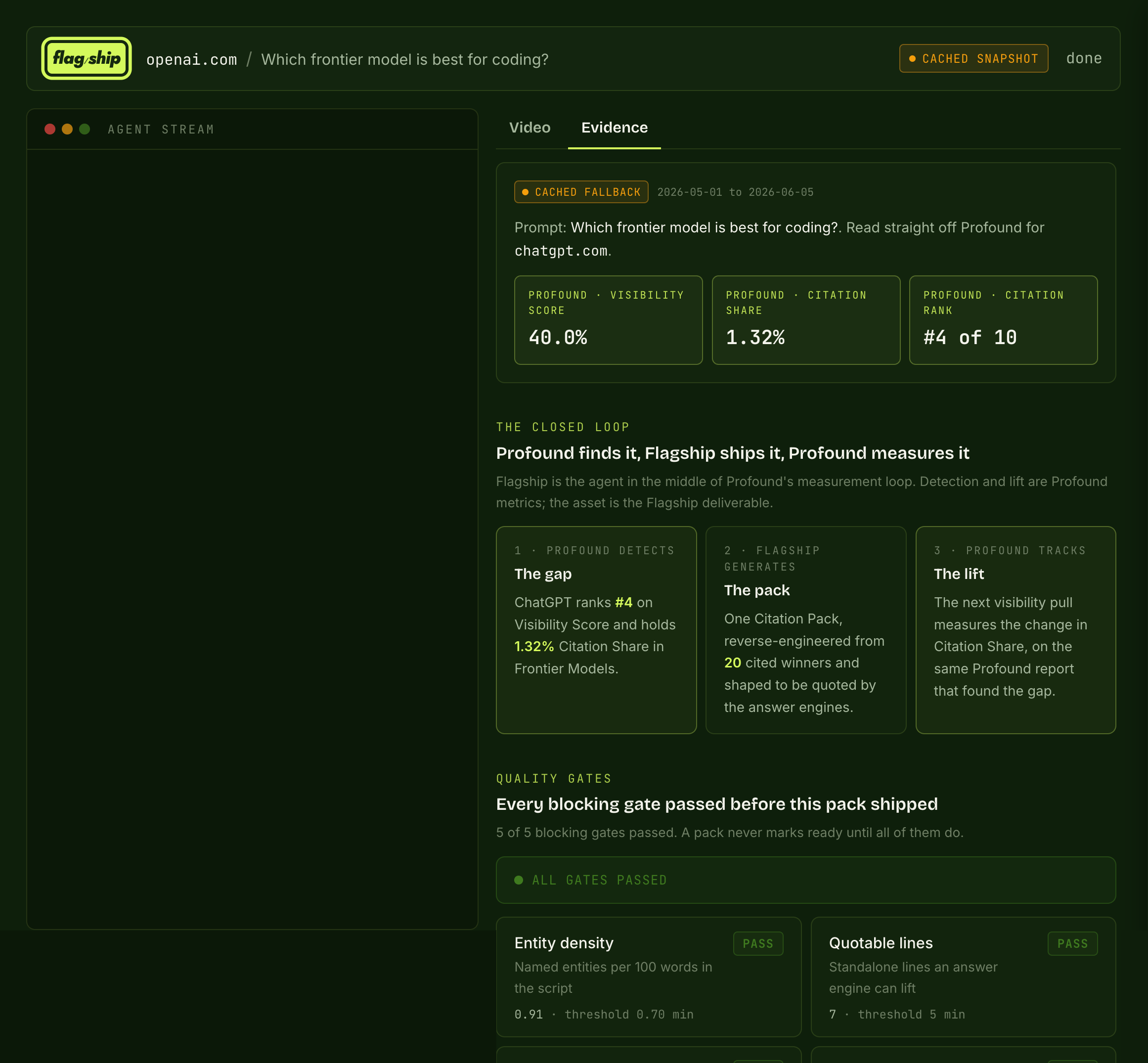
And it worked. It produced the video with HyperFrames and ran the analytics behind it, pulling the Profound visibility scores back in so every pack is tied to the gap it closed.
The part nobody puts in the recap
Here's what actually happened during those eight hours.
I leaned on Claude to move fast: shaping the idea, the product, the design, the troubleshooting. And I made a mess of it.
I was running multiple goals across the day, and they started doing the same work and overwriting each other. Two agents, same files, conflicting versions. I'd fix one thing and another run would quietly undo it. At one point I had to stop, throw work away, and redo it.
That cost me real time on a day where time was the whole game.
It wasn't "AI is unreliable." It was that I wasn't systematic. I pointed agents at overlapping work with no guardrails and got exactly what that setup produces: inconsistent, conflicting output I couldn't trust or hand off.
The system I'm taking into the next build
If you're building with AI agents (vibecoding, Claude Code, whatever you call it) this is what I'd do differently, and what I'll run by default now:
- Plan before you spawn. Your job isn't execution anymore, it's planning. Write the spec first. Agents should execute a plan, not invent one mid-run.
- One agent, one workstream, one set of files. Overlapping goals on shared files will clobber each other. Separation of responsibilities is the thing that keeps parallel work from eating itself.
- Put the constraints in writing, up front. A rules file the agents read every time. That's how quality and context hold up as work scales instead of drifting every run.
- Commit between steps. Checkpoint often, so a bad run is a reset, not an hour of redone work.
- Only parallelize what's actually independent. If two tasks touch the same state, sequence them. Parallel is for genuinely separate workstreams.
None of this is exotic. It's the difference between AI as a slot machine and AI as infrastructure.
By the numbers
| Stage | Number |
|---|---|
| Applied | 250 |
| Selected to build | 50 |
| Pitched in the finals | 8 |
| Winning teams | 2 |
| Hours to build | 8 |
| Minutes to pitch | 4 |
I made the final eight. Two teams won. I wasn't one of them.
Didn't matter as much as I expected. I walked out with a working prototype, a sharper idea, and a day of reps pitching to a room I'd have paid to be in.
The takeaway that stuck
The barrier to building is basically gone. With these tools, almost anyone can stand up a working product in a day. I just did, in eight hours, with a workflow I was actively breaking.
So building stops being the moat.
What's still hard is everything after: distribution, getting in front of the right people, knowing how to talk about what you made so it lands. That part doesn't have an API yet.
Which is why Profound's "Marketing Engineer" framing is the most interesting bet I've seen in a while. Build the system, and make people care about it.
That combination is rare right now. And it's badly underpriced.
I'm betting it won't stay that way.